
Key takeaways
- Pharma manages renditions, not knowledge: every asset lives and dies as a layout, and at the scale of Veeva Vault PromoMats nobody can excavate what the files contain by reading them one by one.
- Across Shaman’s extraction work, 70–80% of a typical promotional document is mandatory or previously approved material — pharma content is assembled from a finite set of permitted statements, not written fresh.
- Earlier modular content initiatives stalled for consistent reasons: hand-curated libraries, global scope where compliance is local, and static snapshots of a moving portfolio.
- Shaman Atlas inverts the cost: extraction re-engineers approved Veeva files into a per-market MLR Knowledge Engine that builds itself and stays in lockstep with Vault — with PromoMats remaining the single source of truth.
- One engine powers everything: pre-populated smart templates, Find & Mass Update, repurposing, automated MLR prechecks with X-Ray — and grounded AI, where Aurora composes traceable assembly from approved knowledge.
Pharma manages renditions, not knowledge
Content in life sciences organisations (LSOs) spends its entire life as layout. An email, a detail aid, a webpage, a brochure — each is briefed as a layout, built as a layout, reviewed as annotations on a layout, approved as a layout, and archived as a PDF rendition. Every major system in the stack is organised around that unit: review platforms circulate documents, digital asset management (DAM) platforms store files, agencies deliver final artwork.
This has a cost the industry has learned to stop noticing. A PDF is to knowledge what a printed photograph is to the scene it captures: faithful, recognisable — and inert. You can look at it, but you cannot ask it anything. Which claims does this piece make? Which references support them? Every one of those questions has an answer that must be excavated by a human, reading file by file. At enterprise pharma scale — hundreds of thousands of approved pieces in Veeva Vault PromoMats — nobody excavates. The knowledge simply sits locked. And the squeeze is tightening: omnichannel has multiplied the content every brand must produce, while MLR capacity has stayed flat. An operating model built on humans reading files one by one does not survive that curve.
Pharma content is not written — it is assembled
The layout habit is inherited from consumer marketing, where a document really is mostly free composition. Pharma is different in kind, not just in degree. Promotional content in life sciences is dictated by Medical, Legal and Regulatory requirements: across our extraction work in different brands and markets, 70–80% of a typical promotional document consists of mandatory or previously approved material. Indication and safety wording anchored to the SmPC or local label, contraindications, adverse event reporting statements, prescribing-information links, privacy notices, legal lines, clinical claims each capable of substantiation — none of it is typed fresh. Mandatory and legal statements are reproduced verbatim; medical claims may be adjusted for the audience or the flow of the story, but always from approved wording, never beyond it. What looks like writing is, overwhelmingly, selection from the finite set of things the company is permitted to say.
of a typical promotional document consists of mandatory or previously approved material — across Shaman’s extraction work in different brands and markets.
And it carries structure the layout never shows. A clinical claim never travels alone: it is bonded to its references, footnotes and qualifying statements the way atoms are bonded into a molecule — separate the parts and the compound no longer exists. A safety statement is conditional on market, audience and channel. A legal line traces back to a code of practice, a law, or an internal SOP. Relationships, conditions, provenance, lifecycle: this is the textbook definition of data. It is merely stored as pictures.
The evidence: compliant content is predictable
If most of a document is mandatory or pre-approved, its shape stops being a creative accident and becomes predictable — and predictability is the signature of underlying structure.
We tested this empirically. Mapping 250 promotional emails from the UK market, the same anatomy surfaced again and again: a regulatory strip at the top carrying the audience restriction, prescribing-information link and indication; a hero zone; an editorial body of claim modules, each pairing a headline assertion with supporting evidence, visuals and cited references; and a compliance footer stacking safety information, footnotes, abbreviations, the reference list, full adverse-event reporting — MHRA Yellow Card, in this market — and the legal block down to the approval code — the job bag, in UK practice. Elements recurred at near-fixed positions, in near-fixed wording, with near-fixed relationships. An experienced reviewer can specify most of a compliant email before anyone opens an editor — and the same holds for a detail aid or a landing page.
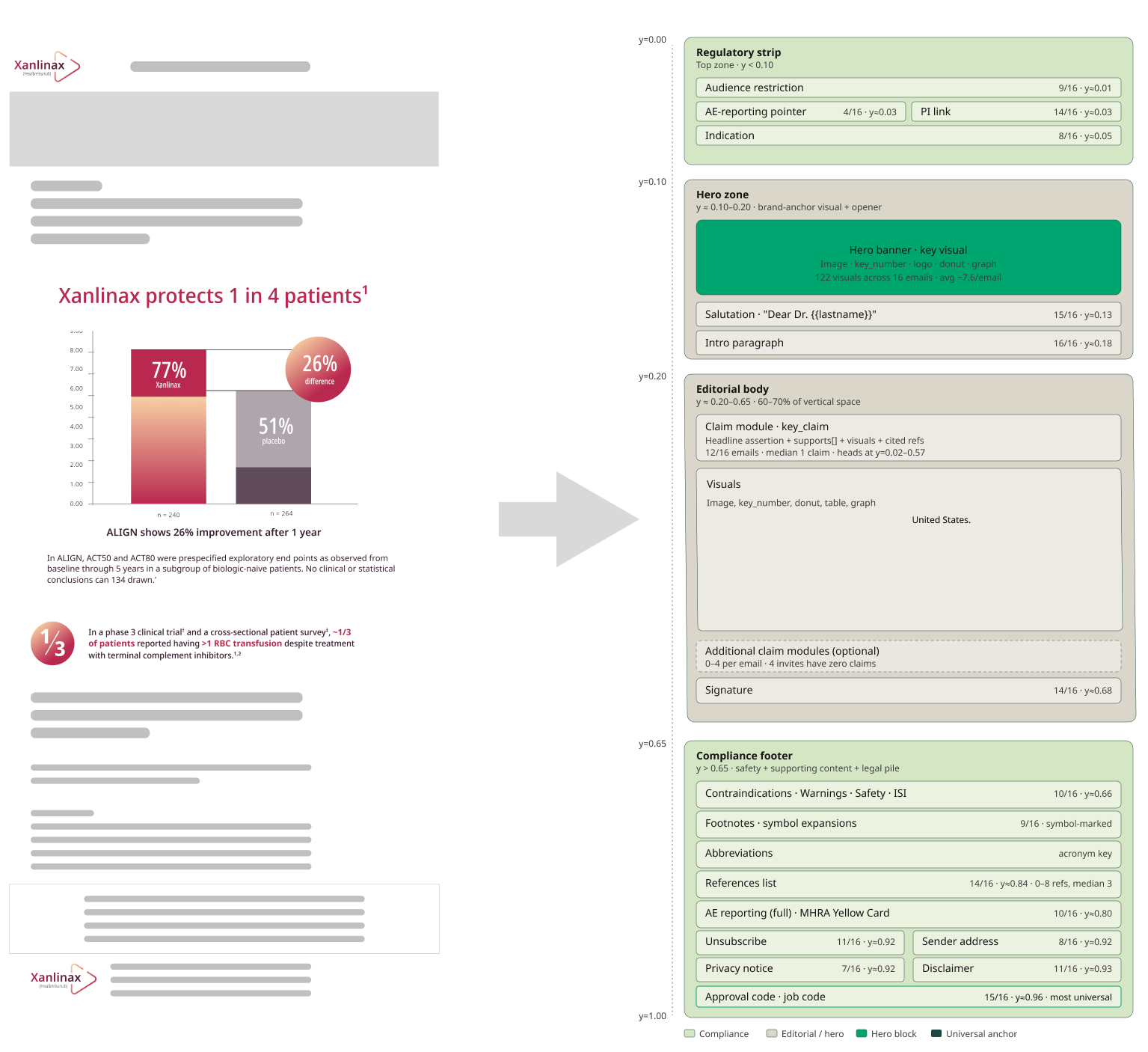
A document whose contents can be anticipated, enumerated and validated by rules is not really a document anymore. It is a dataset wearing a layout.
The insight: treat content as what it is
So invert the model. The layout is a rendering; the knowledge is the asset. Decompose approved content into its constituent elements — claims, evidence, visuals, references, footnotes, regulatory and legal statements — and hold each as machine-readable data with its relationships, its market context and its approval status. Questions that used to require archaeology become queries, and every role in the content chain has its own. A reviewer asks: has this marketing claim been approved before, in what context, and is its supporting evidence complete and its referencing validated? Has this indication wording been approved before? Are all mandatory legal statements in, and is this the current safety wording or a superseded variant? An author asks: which regulatory statements are mandatory in this market, what conditions attach to them, and can my template arrive pre-populated with the approved wording? A content owner asks: where else does this statement live — which assets, markets and channels — and if this reference is superseded, what exactly is affected? A brand lead asks: which key messages are actually being reused, and which claims rest on ageing evidence?
None of these questions is answerable with files. Every one of them is a simple query against data.
A governed home: the MLR Knowledge Engine
Structured knowledge needs somewhere governed to live. We call it the MLR Knowledge Engine, and it deliberately operates at the level where compliance itself operates: per market, per brand. That scoping is also where the money is: most production cost in pharma burns in the gap between global creation and local adaptation, and every adaptation is judged against rules that exist only at market level. An engine scoped globally answers the wrong questions.
The engine holds two libraries. The Mandatory Statements library contains the regulatory and legal material a compliant asset must carry, aligned per market with the local code of practice (the ABPI Code in the UK, for instance), with guidance from regulators such as the FDA, the EMA and national authorities, with applicable law such as GDPR, and with the company’s own SOPs. The Marketing Claims library contains the medical content: key-message headers, their supporting evidence in text and visuals, supporting copy, and the references and footnotes bonded to each claim.
Mandatory Statements library
The regulatory and legal material a compliant asset must carry — aligned per market with the local code of practice, guidance from regulators such as the FDA and the EMA, applicable law such as GDPR, and the company’s own SOPs.
Marketing Claims library
The medical content: key-message headers, their supporting evidence in text and visuals, supporting copy, and the references and footnotes bonded to each claim.
Critically, the engine does not reduce each requirement to a single canonical sentence. It holds the set of company-approved variants that legitimately exist for a statement or claim in a market — because that is how approved content behaves in reality. The same adverse event reporting statement appears in several sanctioned wordings; each is valid, each is traceable, and knowing all of them is precisely what makes finding, matching and mass-updating possible.
The obvious objection
The industry has chased structured reuse before. Modular content initiatives promised libraries of pre-approved blocks — and, in most organisations, stalled. The reasons are remarkably consistent: the libraries had to be curated by hand, which no team could sustain; they were built globally while compliance is enforced locally; and they were static snapshots of a portfolio that never stops moving. Even Veeva Modular Content and the Veeva Claims Library remain document-scoped: valuable within an approval workflow, but not a governed, cross-channel knowledge layer. A structured MLR library has always been the library nobody could build by hand.
That diagnosis matters, because it isolates the real problem. The idea of the library was never wrong. The cost of building and maintaining it was prohibitive.
Shaman Atlas: the library that builds itself
Here is the observation that unlocks everything: the library already exists. Every statement, claim, reference and rule a company needs has already been written, reviewed and approved — thousands of times over — inside the documents sitting in Veeva Vault PromoMats. It is simply stored in the wrong form.
Shaman Atlas starts from that fact. Atlas Extraction re-engineers approved flat files back into structured data: classifying text blocks and visuals, grouping claims with their evidence, resolving references and footnotes, and separating regulatory and legal statements from medical content. Every extracted element carries provenance — a link to its source Veeva document and that document’s lifecycle status — and flows into the Knowledge Engine, where it is canonicalised, deduplicated, matched to local requirements and enriched, with a human in the loop wherever judgement is required.
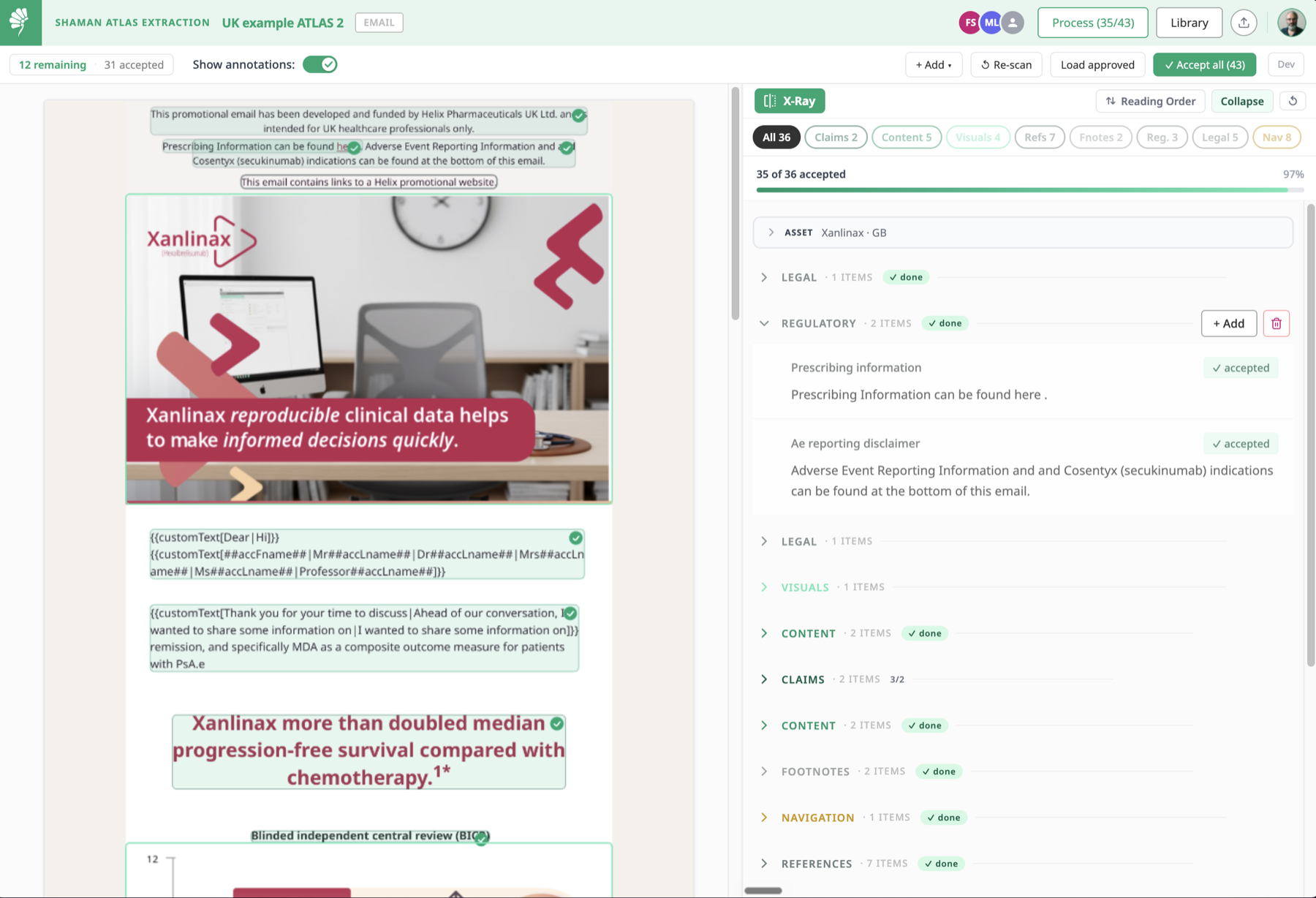
Two properties follow, and both are essential. First, Veeva Vault PromoMats remains the single source of truth: the engine holds knowledge derived from approved documents, never a competing record of approval. Second, the engine is alive. It stays in lockstep with Veeva — every newly approved piece is extracted automatically, and when a source document expires, its derived elements are flagged and retracted. The library that was too expensive to build by hand now builds itself, at local market level, and keeps itself current. Self-building is not self-governing: content owners still curate exceptions and confirm matches — but their work shifts from assembling a library to exercising judgement over one.

The name is deliberate. An atlas does not invent territory; it makes territory navigable. Atlas does not create your approved content — it turns what you already own into something you can finally search, govern and reuse.
One engine, working everywhere
A knowledge engine is only as valuable as what runs on it, which is why Atlas is not a standalone repository but the substrate of the Shaman platform. In authoring, smart templates arrive pre-populated with the mandatory statements for the target market and brand, and update automatically when content is localised. Find & Mass Update searches approved variants — an adverse event reporting statement, an indication, a contraindication — across the entire estate and propagates a change in one action instead of one project per file. Repurposing turns a single approved source into new channels and formats, because the underlying elements are portable in a way layouts never were. And MLR X-Ray — an automated MLR precheck — reads a draft the way the engine reads approved content — as structured claims and statements — showing review teams what already matches approved knowledge, what partially matches, and what is genuinely new. Reviewers stop re-reading what was approved long ago and concentrate their judgement where it is actually needed.
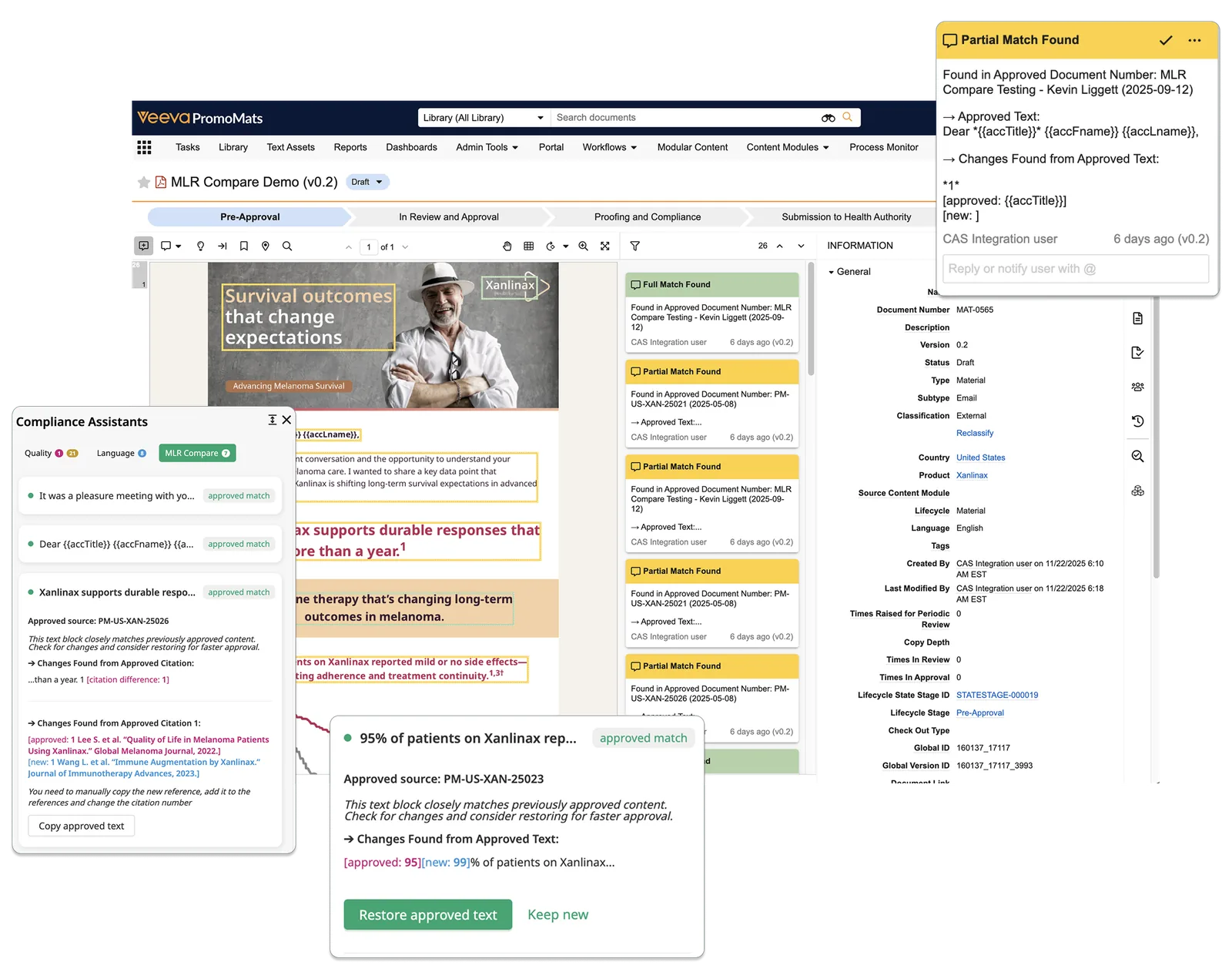
The chain of effects is the business case: more reuse means less net-new content; less net-new means a smaller review scope; a smaller scope means shorter cycle times and campaigns in market sooner. These are the metrics content excellence teams already track — reuse rate, first-time-right approvals, cost per asset, time to market. It also resets the agency question: when compliance assembly is handled by the platform, agencies are briefed for what they are genuinely for — creative and strategy — and everyday content becomes self-service.
The foundation AI was waiting for
Generative AI’s weakness in regulated content is well understood: a general-purpose model produces fluent language with no notion of what your company is approved to say. In pharma, that is not an inconvenience. It is disqualifying.
Grounding changes the equation entirely. Because Aurora — Shaman’s agentic AI — composes from the Knowledge Engine, its output is not plausible text but traceable assembly: approved claims with their bonded references, mandatory statements matched to the target market, every element carrying provenance back to an approved source. Not a black box; a glass one. This, we believe, is the decisive line between AI as a compliance risk and AI as a compounding advantage — and it is why the durable value in AI content production sits in the knowledge layer, not the generation layer. Models will keep improving for everyone. A governed engine of your own approved knowledge improves only for you.
Where this sits in the stack
The Knowledge Engine replaces nothing; it completes something. Review-and-approval systems — Veeva Vault PromoMats above all — govern documents through MLR review and approval and remain the system of record. DAMs such as Veeva and Aprimo govern visual assets, and do that well. Both are built around finished files, and neither treats the regulated language inside those files — the claims, statements and references where pharma’s risk and value actually concentrate — as governed data. In this industry, the words are more consequential than the pictures.
That missing layer belongs with authoring, because authoring is the moment knowledge becomes content: where elements are selected, combined and rendered for a channel. The stack that emerges is clean and complementary — a content supply chain in which Veeva governs approval, the DAM governs visuals, and the MLR Knowledge Engine governs the knowledge every new asset is built from.
Obvious in retrospect
When we walk pharmaceutical teams through this argument, the most common reaction is not surprise but recognition: of course approved content is structured data — it always was. That is what sound foundations feel like: obvious in retrospect, and invisible until someone builds them.
The industry standardised on layout because, until recently, recovering structure from hundreds of thousands of flat files was simply not feasible. It now is — and Shaman has spent more than a decade in pharma content authoring building toward exactly this moment. Atlas is live: extraction, the Knowledge Engine, and the services that consume it. Your approved content has spent years locked inside its own renditions. The teams that unlock it first will set the pace for everyone else.
Frequently asked questions
What is an MLR Knowledge Engine?
A governed, market- and brand-scoped store of the knowledge inside approved pharma content. It holds two libraries — mandatory regulatory and legal statements aligned to the local code of practice, and marketing claims with their bonded evidence, references and footnotes — including every company-approved variant of each statement, with provenance back to the source Veeva document.
How is Shaman Atlas different from earlier modular content initiatives?
Modular content libraries stalled because they were curated by hand, built globally while compliance is enforced locally, and static. Atlas extracts the library automatically from content already approved in Veeva Vault PromoMats, scopes it per market and brand, and keeps it in lockstep with Veeva: newly approved pieces flow in automatically, and when a source document expires its derived elements are flagged and retracted.
Does the MLR Knowledge Engine replace Veeva Vault PromoMats?
No. Veeva Vault PromoMats remains the single source of truth for approval, and DAMs continue to govern visual assets. The engine holds knowledge derived from approved documents — never a competing record of approval — and completes the stack as the layer new content is built from.
How does Shaman Atlas make generative AI compliant in pharma?
Aurora, Shaman’s agentic AI, composes from the Knowledge Engine rather than producing free text: approved claims with their bonded references, mandatory statements matched to the target market, and provenance back to an approved source on every element — traceable assembly instead of plausible language.
Sources: Shaman extraction data across brands and markets (70–80% mandatory or previously approved material); internal mapping of 250 promotional emails from the UK market; more than a decade of Shaman implementations on Veeva Vault PromoMats.


